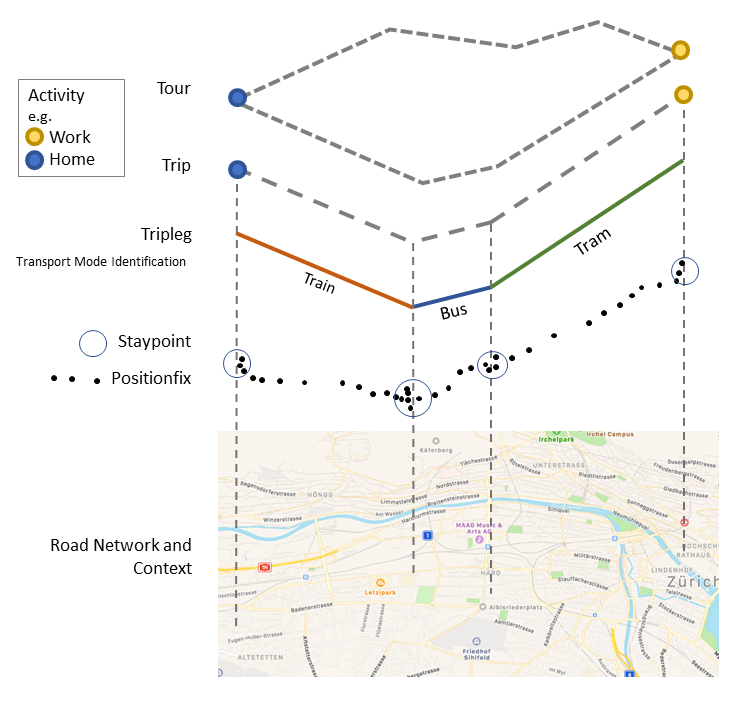
Model
In trackintel, tracking data is split into several classes. It is not generally
assumed that data is already available in all these classes, instead, trackintel
provides functionality to generate everything starting from the raw GPS positionfix data
(consisting of at least (user_id, tracked_at, longitude, latitude) tuples).
positionfixes: Raw GPS data.
staypoints: Locations where a user spent a minimal time.
triplegs: Segments covered with one mode of transport.
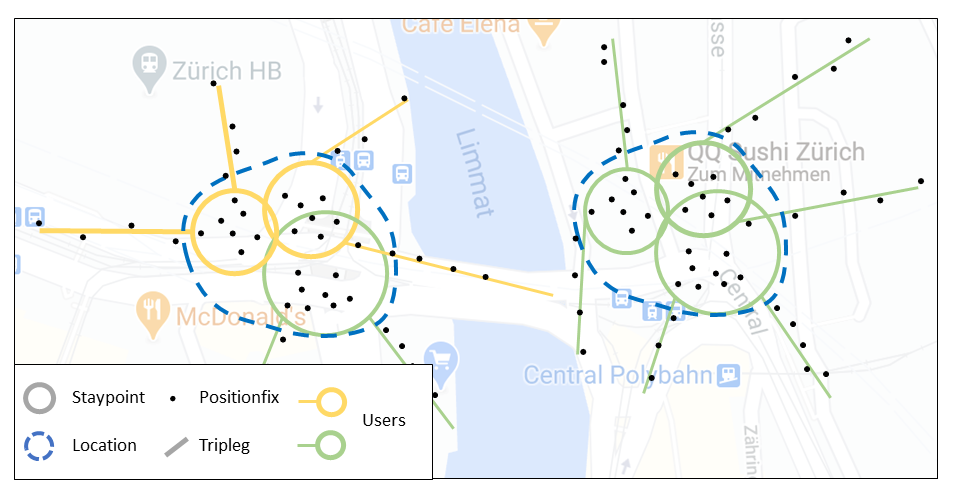
locations: Clustered staypoints.
trips: Segments between consecutive activity staypoints (special staypoints that are not just waiting points).
tours: Sequences of trips which start and end at the same location (if the column ‘journey’ is True, this location is home).
An example plot showing the hierarchy of the trackintel data model can be found below:
The image below explicitly shows the definition of locations as clustered staypoints, generated by one or several users.
A detailed (and SQL-specific) explanation of the different classes can be found under data_model.
GeoPandas Implementation
In trackintel we provide 5 classes that subclass DataFrames or GeoDataFrames, depending if there is a geometry or not. That means all trackintel classes work like (Geo)DataFrames with some additional features, like: data validation and new methods for analyzing mobility data. For example:
df = trackintel.read_positionfixes_csv('data.csv')
df.generate_staypoints()
This will read a CSV into a Positionfixes trackintel class and validate the input data corresponding to
our model. This allows access to the trackintel methods such as generate_staypoints().
Trackintel Classes
The following classes are implemented within trackintel.
Positionfixes
- class trackintel.Positionfixes(*args, validate=True, **kwargs)[source]
Trackintel class to treat GeoDataFrames as collections of Positionfixes.
Requires at least the following columns: [‘user_id’, ‘tracked_at’]
Requires valid point geometries; the ‘index’ of the GeoDataFrame will be treated as unique identifier of the Positionfixes.
For several usecases, the following additional columns are required: [‘elevation’, ‘accuracy’ ‘staypoint_id’, ‘tripleg_id’]
Notes
In GPS based movement data analysis Positionfixes are the smallest unit of tracking and represent timestamped locations.
‘tracked_at’ is a timezone aware pandas datetime object.
Examples
>>> positionfixes.generate_staypoints()
- property as_positionfixes
Trackintel class to treat GeoDataFrames as collections of Positionfixes.
Requires at least the following columns: [‘user_id’, ‘tracked_at’]
Requires valid point geometries; the ‘index’ of the GeoDataFrame will be treated as unique identifier of the Positionfixes.
For several usecases, the following additional columns are required: [‘elevation’, ‘accuracy’ ‘staypoint_id’, ‘tripleg_id’]
Notes
In GPS based movement data analysis Positionfixes are the smallest unit of tracking and represent timestamped locations.
‘tracked_at’ is a timezone aware pandas datetime object.
Examples
>>> positionfixes.generate_staypoints()
- calculate_distance_matrix(Y=None, dist_metric='haversine', n_jobs=0, **kwds)[source]
Calculate a distance matrix based on a specific distance metric.
See
trackintel.geogr.calculate_distance_matrix()for full documentation.
- property center
Return the center coordinate of this collection of positionfixes.
- generate_staypoints(method='sliding', distance_metric='haversine', dist_threshold=100, time_threshold=5.0, gap_threshold=15.0, include_last=False, print_progress=False, exclude_duplicate_pfs=True, n_jobs=1)[source]
Generate staypoints based on positionfixes.
See
trackintel.preprocessing.generate_staypoints()for full documentation.
- generate_triplegs(staypoints=None, method='between_staypoints', gap_threshold=15)[source]
Generate triplegs from positionfixes.
See
trackintel.preprocessing.generate_triplegs()for full documentation.
- get_speed()[source]
Compute speed per positionfix (in m/s)
See
trackintel.geogr.get_speed_positionfixes()for full documentation.
- to_csv(filename, *args, **kwargs)[source]
Write positionfixes to csv file.
See
trackintel.io.write_positionfixes_csv()for full documentation.
- to_postgis(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)[source]
Stores positionfixes to PostGIS. Usually, this is directly called on a positionfixes DataFrame (see example below).
- Parameters:
name (str) – The name of the table to write to.
con (sqlalchemy.engine.Connection or sqlalchemy.engine.Engine) – active connection to PostGIS database.
schema (str, optional) – The schema (if the database supports this) where the table resides.
if_exists (str, {'fail', 'replace', 'append'}, default 'fail') –
How to behave if the table already exists.
fail: Raise a ValueError.
replace: Drop the table before inserting new values.
append: Insert new values to the existing table.
index (bool, default True) – Write DataFrame index as a column. Uses index_label as the column name in the table.
index_label (str or sequence, default None) – Column label for index column(s). If None is given (default) and index is True, then the index names are used.
chunksize (int, optional) – How many entries should be written at the same time.
dtype (dict of column name to SQL type, default None) – Specifying the datatype for columns. The keys should be the column names and the values should be the SQLAlchemy types.
Examples
>>> pfs.to_postgis(conn_string, table_name) >>> ti.io.write_positionfixes_postgis(pfs, conn_string, table_name)
Staypoints
- class trackintel.Staypoints(*args, validate=True, **kwargs)[source]
Trackintel class to treat a GeoDataFrame as collections of Staypoints.
Requires at least the following columns: [‘user_id’, ‘started_at’, ‘finished_at’]
Requires valid point geometries; the ‘index’ of the GeoDataFrame will be treated as unique identifier of the Staypoints.
For several usecases, the following additional columns are required: [‘elevation’, ‘purpose’, ‘is_activity’, ‘next_trip_id’, ‘prev_trip_id’, ‘trip_id’, location_id]
Notes
Staypoints are defined as location were a person did not move for a while. Under consideration of location uncertainty this means that a person stays within a close proximity for a certain amount of time. The exact definition is use-case dependent.
‘started_at’ and ‘finished_at’ are timezone aware pandas datetime objects.
Examples
>>> staypoints.generate_locations()
- property as_staypoints
Trackintel class to treat a GeoDataFrame as collections of Staypoints.
Requires at least the following columns: [‘user_id’, ‘started_at’, ‘finished_at’]
Requires valid point geometries; the ‘index’ of the GeoDataFrame will be treated as unique identifier of the Staypoints.
For several usecases, the following additional columns are required: [‘elevation’, ‘purpose’, ‘is_activity’, ‘next_trip_id’, ‘prev_trip_id’, ‘trip_id’, location_id]
Notes
Staypoints are defined as location were a person did not move for a while. Under consideration of location uncertainty this means that a person stays within a close proximity for a certain amount of time. The exact definition is use-case dependent.
‘started_at’ and ‘finished_at’ are timezone aware pandas datetime objects.
Examples
>>> staypoints.generate_locations()
- property center
Return the center coordinate of this collection of staypoints.
- create_activity_flag(method='time_threshold', time_threshold=15.0, activity_column_name='is_activity')[source]
Add a flag whether or not a staypoint is considered an activity based on a time threshold.
See
trackintel.analysis.create_activity_flag()for full documentation.
- generate_locations(method='dbscan', epsilon=100, num_samples=1, distance_metric='haversine', agg_level='user', activities_only=False, print_progress=False, n_jobs=1)[source]
Generate locations from the staypoints.
See
trackintel.preprocessing.generate_locations()for full documentation.
- generate_trips(triplegs, gap_threshold=15, add_geometry=True)[source]
Generate trips based on staypoints and triplegs.
See
trackintel.preprocessing.generate_trips()for full documentation.
- jump_length()[source]
Calculate jump length per user between consecutive staypoints.
See
trackintel.analysis.jump_length()for full documentation.
- merge_staypoints(triplegs, max_time_gap='10min', agg={})[source]
Aggregate staypoints horizontally via time threshold.
See
trackintel.preprocessing.merge_staypoints()for full documentation.
- radius_gyration(method='count', print_progress=False)[source]
Calculate radius for gyration for Staypoints
See
trackintel.analysis.radius_gyration()for full documentation.
- spatial_filter(areas, method='within', re_project=False)[source]
Filter Staypoints on a geo extent.
See
trackintel.geogr.spatial_filter()for full documentation.
- temporal_tracking_quality(granularity='all')[source]
Calculate per-user temporal tracking quality (temporal coverage).
See
trackintel.analysis.temporal_tracking_quality()for full documentation.
- to_csv(filename, *args, **kwargs)[source]
Write staypoints to csv file.
Wraps the pandas to_csv function. Geometry get transformed to WKT before writing.
- Parameters:
filename (str) – The file to write to.
args – Additional arguments passed to pd.DataFrame.to_csv().
kwargs – Additional keyword arguments passed to pd.DataFrame.to_csv().
Examples
>>> sp.to_csv("export_staypoints.csv")
- to_postgis(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)[source]
Stores staypoints to PostGIS. Usually, this is directly called on a staypoints DataFrame (see example below).
- Parameters:
name (str) – The name of the table to write to.
con (sqlalchemy.engine.Connection or sqlalchemy.engine.Engine) – active connection to PostGIS database.
schema (str, optional) – The schema (if the database supports this) where the table resides.
if_exists (str, {'fail', 'replace', 'append'}, default 'fail') –
How to behave if the table already exists.
fail: Raise a ValueError.
replace: Drop the table before inserting new values.
append: Insert new values to the existing table.
index (bool, default True) – Write DataFrame index as a column. Uses index_label as the column name in the table.
index_label (str or sequence, default None) – Column label for index column(s). If None is given (default) and index is True, then the index names are used.
chunksize (int, optional) – How many entries should be written at the same time.
dtype (dict of column name to SQL type, default None) – Specifying the datatype for columns. The keys should be the column names and the values should be the SQLAlchemy types.
Examples
>>> sp.to_postgis(conn_string, table_name) >>> ti.io.write_staypoints_postgis(sp, conn_string, table_name)
Triplegs
- class trackintel.Triplegs(*args, validate=True, **kwargs)[source]
Trackintel class to treat a GeoDataFrame as a collections of Tripleg.
Requires at least the following columns: [‘user_id’, ‘started_at’, ‘finished_at’]
Requires valid line geometries; the ‘index’ of the GeoDataFrame will be treated as unique identifier of the triplegs
For several usecases, the following additional columns are required: [‘mode’, ‘trip_id’]
Notes
A Tripleg (also called stage) is defined as continuous movement without changing the mode of transport.
‘started_at’ and ‘finished_at’ are timezone aware pandas datetime objects.
Examples
>>> triplegs.generate_trips()
- property as_triplegs
Trackintel class to treat a GeoDataFrame as a collections of Tripleg.
Requires at least the following columns: [‘user_id’, ‘started_at’, ‘finished_at’]
Requires valid line geometries; the ‘index’ of the GeoDataFrame will be treated as unique identifier of the triplegs
For several usecases, the following additional columns are required: [‘mode’, ‘trip_id’]
Notes
A Tripleg (also called stage) is defined as continuous movement without changing the mode of transport.
‘started_at’ and ‘finished_at’ are timezone aware pandas datetime objects.
Examples
>>> triplegs.generate_trips()
- calculate_distance_matrix(Y=None, dist_metric='haversine', n_jobs=0, **kwds)[source]
Calculate a distance matrix based on a specific distance metric.
See
trackintel.geogr.calculate_distance_matrix()for full documentation.
- calculate_modal_split(freq=None, metric='count', per_user=False, norm=False)[source]
Calculate the modal split of triplegs.
See
trackintel.analysis.calculate_modal_split()for full documentation.
- generate_trips(staypoints, gap_threshold=15, add_geometry=True)[source]
Generate trips based on staypoints and triplegs.
See
trackintel.preprocessing.generate_trips()for full documentation.
- get_speed(positionfixes=None, method='tpls_speed')[source]
Compute the average speed per positionfix for each tripleg (in m/s)
See
trackintel.geogr.get_speed_triplegs()for full documentation.
- predict_transport_mode(method='simple-coarse', **kwargs)[source]
Predict the transport mode of triplegs.
See
trackintel.analysis.predict_transport_mode()for full documentation.
- spatial_filter(areas, method='within', re_project=False)[source]
Filter Triplegs on a geo extent.
See
trackintel.geogr.spatial_filter()for full documentation.
- temporal_tracking_quality(granularity='all')[source]
Calculate per-user temporal tracking quality (temporal coverage).
See
trackintel.analysis.temporal_tracking_quality()for full documentation.
- to_csv(filename, *args, **kwargs)[source]
Write triplegs to csv file.
Wraps the pandas to_csv function. Geometry get transformed to WKT before writing.
- Parameters:
filename (str) – The file to write to.
args – Additional arguments passed to pd.DataFrame.to_csv().
kwargs – Additional keyword arguments passed to pd.DataFrame.to_csv().
Examples
>>> tpls.to_csv("export_triplegs.csv")
- to_postgis(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)[source]
Stores triplegs to PostGIS. Usually, this is directly called on a triplegs DataFrame (see example below).
- Parameters:
name (str) – The name of the table to write to.
con (sqlalchemy.engine.Connection or sqlalchemy.engine.Engine) – active connection to PostGIS database.
schema (str, optional) – The schema (if the database supports this) where the table resides.
if_exists (str, {'fail', 'replace', 'append'}, default 'fail') –
How to behave if the table already exists.
fail: Raise a ValueError.
replace: Drop the table before inserting new values.
append: Insert new values to the existing table.
index (bool, default True) – Write DataFrame index as a column. Uses index_label as the column name in the table.
index_label (str or sequence, default None) – Column label for index column(s). If None is given (default) and index is True, then the index names are used.
chunksize (int, optional) – How many entries should be written at the same time.
dtype (dict of column name to SQL type, default None) – Specifying the datatype for columns. The keys should be the column names and the values should be the SQLAlchemy types.
Examples
>>> tpls.to_postgis(conn_string, table_name) >>> ti.io.write_triplegs_postgis(tpls, conn_string, table_name)
Locations
- class trackintel.Locations(*args, validate=True, **kwargs)[source]
Trackintel class to treat a GeoDataFrames as a collections of locations.
Requires at least the following columns: [‘user_id’, ‘center’]
For several usecases, the following additional columns are required: [‘elevation’, ‘extent’]
Notes
Locations are spatially aggregated Staypoints where a user frequently visits.
Examples
>>> locations.to_csv("filename.csv")
- property as_locations
Trackintel class to treat a GeoDataFrames as a collections of locations.
Requires at least the following columns: [‘user_id’, ‘center’]
For several usecases, the following additional columns are required: [‘elevation’, ‘extent’]
Notes
Locations are spatially aggregated Staypoints where a user frequently visits.
Examples
>>> locations.to_csv("filename.csv")
- spatial_filter(areas, method='within', re_project=False)[source]
Filter Locations on a geo extent.
See
trackintel.geogr.spatial_filter()for full documentation.
- to_csv(filename, *args, **kwargs)[source]
Write locations to csv file.
Wraps the pandas to_csv function. Geometry get transformed to WKT before writing.
- Parameters:
filename (str) – The file to write to.
args – Additional arguments passed to pd.DataFrame.to_csv().
kwargs – Additional keyword arguments passed to pd.DataFrame.to_csv().
Examples
>>> locs.to_csv("export_locations.csv")
- to_postgis(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)[source]
Stores locations to PostGIS. Usually, this is directly called on a locations DataFrame (see example below).
- Parameters:
name (str) – The name of the table to write to.
con (sqlalchemy.engine.Connection or sqlalchemy.engine.Engine) – active connection to PostGIS database.
schema (str, optional) – The schema (if the database supports this) where the table resides.
if_exists (str, {'fail', 'replace', 'append'}, default 'fail') –
How to behave if the table already exists.
fail: Raise a ValueError.
replace: Drop the table before inserting new values.
append: Insert new values to the existing table.
index (bool, default True) – Write DataFrame index as a column. Uses index_label as the column name in the table.
index_label (str or sequence, default None) – Column label for index column(s). If None is given (default) and index is True, then the index names are used.
chunksize (int, optional) – How many entries should be written at the same time.
dtype (dict of column name to SQL type, default None) – Specifying the datatype for columns. The keys should be the column names and the values should be the SQLAlchemy types.
Examples
>>> locs.to_postgis(conn_string, table_name) >>> ti.io.write_locations_postgis(locs, conn_string, table_name)
Trips
- class trackintel.Trips(*args, **kwargs)[source]
Trackintel class to treat (Geo)DataFrames as collections of trips.
The class constructor will create a TripsDataFrame or a TripsGeoDataFrame depending if a geometry column is present.
Requires at least the following columns: [‘user_id’, ‘started_at’, ‘finished_at’, ‘origin_staypoint_id’, ‘destination_staypoint_id’]
The ‘index’ of the (Geo)DataFrame will be treated as unique identifier of the Trips
Trips have an optional geometry of type MultiPoint which describes the start and the end point of the trip
For several usecases, the following additional columns are required: [‘origin_purpose’, ‘destination_purpose’, ‘modes’, ‘primary_mode’, ‘tour_id’]
Notes
Trips are an aggregation level in transport planning that summarize all movement and all non-essential actions (e.g., waiting) between two relevant activities. The following assumptions are implemented
If we do not record a person for more than gap_threshold minutes, we assume that the person performed an activity in the recording gap and split the trip at the gap.
Trips that start/end in a recording gap can have an unknown origin/destination staypoint id.
If the origin (or destination) staypoint is unknown (and a geometry column exists), the origin/destination geometry is set as the first coordinate of the first tripleg (or the last coordinate of the last tripleg)
There are no trips without a (recorded) tripleg.
‘started_at’ and ‘finished_at’ are timezone aware pandas datetime objects.
Examples
>>> trips.generate_tours()
Tours
- class trackintel.Tours(*args, validate=True, **kwargs)[source]
Trackintel class to treat DataFrames as collections of Tours.
Requires at least the following columns: [‘user_id’, ‘started_at’, ‘finished_at’]
The ‘index’ of the DataFrame will be treated as unique identifier of the Tours
For several usecases, the following additional columns are required: [‘location_id’, ‘journey’, ‘origin_staypoint_id’, ‘destination_staypoint_id’]
Notes
Tours are an aggregation level in transport planning that summarize all trips until a person returns to the same location. Tours starting and ending at home (=journey) are especially important.
‘started_at’ and ‘finished_at’ are timezone aware pandas datetime objects.
Examples
>>> tours.to_csv("filename.csv")
- property as_tours
Trackintel class to treat DataFrames as collections of Tours.
Requires at least the following columns: [‘user_id’, ‘started_at’, ‘finished_at’]
The ‘index’ of the DataFrame will be treated as unique identifier of the Tours
For several usecases, the following additional columns are required: [‘location_id’, ‘journey’, ‘origin_staypoint_id’, ‘destination_staypoint_id’]
Notes
Tours are an aggregation level in transport planning that summarize all trips until a person returns to the same location. Tours starting and ending at home (=journey) are especially important.
‘started_at’ and ‘finished_at’ are timezone aware pandas datetime objects.
Examples
>>> tours.to_csv("filename.csv")
- to_csv(filename, *args, **kwargs)[source]
Write tours to csv file.
Wraps the pandas to_csv function. Geometry get transformed to WKT before writing.
- Parameters:
filename (str) – The file to write to.
args – Additional arguments passed to pd.DataFrame.to_csv().
kwargs – Additional keyword arguments passed to pd.DataFrame.to_csv().
Examples
>>> tours.to_csv("export_tours.csv")
- to_postgis(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)[source]
Stores tours to PostGIS. Usually, this is directly called on a tours DataFrame (see example below).
- Parameters:
name (str) – The name of the table to write to.
con (sqlalchemy.engine.Connection or sqlalchemy.engine.Engine) – active connection to PostGIS database.
schema (str, optional) – The schema (if the database supports this) where the table resides.
if_exists (str, {'fail', 'replace', 'append'}, default 'fail') –
How to behave if the table already exists.
fail: Raise a ValueError.
replace: Drop the table before inserting new values.
append: Insert new values to the existing table.
index (bool, default True) – Write DataFrame index as a column. Uses index_label as the column name in the table.
index_label (str or sequence, default None) – Column label for index column(s). If None is given (default) and index is True, then the index names are used.
chunksize (int, optional) – How many entries should be written at the same time.
dtype (dict of column name to SQL type, default None) – Specifying the datatype for columns. The keys should be the column names and the values should be the SQLAlchemy types.
Examples
>>> tours.to_postgis(conn_string, table_name) >>> ti.io.write_tours_postgis(tours, conn_string, table_name)
Data Model (SQL)
For a general description of the data model, please refer to the Model. You can download the complete SQL script here in case you want to quickly set up a database. Also take a look at the example on github.
The positionfixes table contains all positionfixes (i.e., all individual GPS trackpoints, consisting of longitude, latitude and timestamp) of all users. They are not only linked to a user, but also (potentially, if this link has already been made) to a tripleg or a staypoint:
CREATE TABLE positionfixes (
-- Common to all tables.
id bigint NOT NULL,
user_id bigint NOT NULL,
-- References to foreign tables.
tripleg_id bigint,
staypoint_id bigint,
-- Temporal attributes.
tracked_at timestamp with time zone NOT NULL,
-- Spatial attributes.
elevation double precision,
geom geometry(Point, 4326),
-- Constraints.
CONSTRAINT positionfixes_pkey PRIMARY KEY (id)
);
The staypoints table contains all stay points, i.e., points where a user stayed for a certain amount of time. They are linked to a user, as well as (potentially) to a trip and location. Depending on the purpose and time spent, a staypoint can be an activity, i.e., a meaningful destination of movement:
CREATE TABLE staypoints (
-- Common to all tables.
id bigint NOT NULL,
user_id bigint NOT NULL,
-- References to foreign tables.
trip_id bigint,
location_id bigint,
-- Temporal attributes.
started_at timestamp with time zone NOT NULL,
finished_at timestamp with time zone NOT NULL,
-- Attributes related to the activity performed at the staypoint.
purpose_detected character varying,
purpose_validated character varying,
validated boolean,
validated_at timestamp with time zone,
activity boolean,
-- Spatial attributes.
elevation double precision,
geom geometry(Point, 4326),
-- Constraints.
CONSTRAINT staypoints_pkey PRIMARY KEY (id)
);
The triplegs table contains all triplegs, i.e., journeys that have been taken with a single mode of transport. They are linked to both a user, as well as a trip and if applicable, a public transport case:
CREATE TABLE triplegs (
-- Common to all tables.
id bigint NOT NULL,
user_id bigint NOT NULL,
-- References to foreign tables.
trip_id bigint,
-- Temporal attributes.
started_at timestamp with time zone NOT NULL,
finished_at timestamp with time zone NOT NULL,
-- Attributes related to the transport mode used for this tripleg.
mode_detected character varying,
mode_validated character varying,
validated boolean,
validated_at timestamp with time zone,
-- Spatial attributes.
-- The raw geometry is unprocessed, directly made up from the positionfixes. The column
-- 'geom' contains processed (e.g., smoothened, map matched, etc.) data.
geom_raw geometry(Linestring, 4326),
geom geometry(Linestring, 4326),
-- Constraints.
CONSTRAINT triplegs_pkey PRIMARY KEY (id)
);
The locations table contains all locations, i.e., somehow created (e.g., from clustering staypoints) meaningful locations:
CREATE TABLE locations (
-- Common to all tables.
id bigint NOT NULL,
user_id bigint,
-- Spatial attributes.
elevation double precision,
extent geometry(Polygon, 4326),
center geometry(Point, 4326),
-- Constraints.
CONSTRAINT locations_pkey PRIMARY KEY (id)
);
The trips table contains all trips, i.e., collection of trip legs going from one
activity (staypoint with activity==True) to another. They are simply linked to a user:
CREATE TABLE trips (
-- Common to all tables.
id bigint NOT NULL,
user_id integer NOT NULL,
-- References to foreign tables.
origin_staypoint_id bigint,
destination_staypoint_id bigint,
-- Temporal attributes.
started_at timestamp with time zone NOT NULL,
finished_at timestamp with time zone NOT NULL,
-- Constraints.
CONSTRAINT trips_pkey PRIMARY KEY (id)
);
The tours table contains all tours, i.e., sequence of trips which start and end
at the same location (in case of journey==True this location is home).
They are linked to a user:
CREATE TABLE tours (
-- Common to all tables.
id bigint NOT NULL,
user_id integer NOT NULL,
-- References to foreign tables.
location_id bigint,
-- Temporal attributes.
started_at timestamp with time zone NOT NULL,
finished_at timestamp with time zone NOT NULL,
-- Specific attributes.
journey bool,
-- Constraints.
CONSTRAINT tours_pkey PRIMARY KEY (id)
);