Preprocessing
The preprocessing module contains a variety of functions to transform mobility and tracking data into richer data sources.
Positionfixes
As positionfixes are usually the data we receive from a tracking application of some sort, there are various functions that extract meaningful information from it (and in the process turn it into a higher-level trackintel data structure).
In particular, we can generate staypoints and triplegs from positionfixes.
- trackintel.preprocessing.generate_staypoints(positionfixes, method='sliding', distance_metric='haversine', dist_threshold=100, time_threshold=5.0, gap_threshold=15.0, include_last=False, print_progress=False, exclude_duplicate_pfs=True, n_jobs=1)[source]
Generate staypoints from positionfixes.
- Parameters:
positionfixes (Positionfixes)
method ({'sliding'}) – Method to create staypoints. ‘sliding’ applies a sliding window over the data.
distance_metric ({'haversine'}) – The distance metric used by the applied method.
dist_threshold (float, default 100) – The distance threshold for the ‘sliding’ method, i.e., how far someone has to travel to generate a new staypoint. Units depend on the dist_func parameter. If ‘distance_metric’ is ‘haversine’ the unit is in meters
time_threshold (float, default 5.0 (minutes)) – The time threshold for the ‘sliding’ method in minutes.
gap_threshold (float, default 15.0 (minutes)) – The time threshold of determine whether a gap exists between consecutive pfs. Consecutive pfs with temporal gaps larger than ‘gap_threshold’ will be excluded from staypoints generation. Only valid in ‘sliding’ method.
include_last (boolean, default False) – The algorithm in Li et al. (2008) only detects staypoint if the user steps out of that staypoint. This will omit the last staypoint (if any). Set ‘include_last’ to True to include this last staypoint.
print_progress (boolean, default False) – Show per-user progress if set to True.
exclude_duplicate_pfs (boolean, default True) – Filters duplicate positionfixes before generating staypoints. Duplicates can lead to problems in later processing steps (e.g., when generating triplegs). It is not recommended to set this to False.
n_jobs (int, default 1) – The maximum number of concurrently running jobs. If -1 all CPUs are used. If 1 is given, no parallel computing code is used at all, which is useful for debugging. See https://joblib.readthedocs.io/en/latest/parallel.html#parallel-reference-documentation for a detailed description
- Returns:
pfs (Positionfixes) – The original positionfixes with a new column
[`staypoint_id`].sp (Staypoints) – The generated staypoints.
Notes
The ‘sliding’ method is adapted from Li et al. (2008). In the original algorithm, the ‘finished_at’ time for the current staypoint lasts until the ‘tracked_at’ time of the first positionfix outside this staypoint. Users are assumed to be stationary during this missing period and potential tracking gaps may be included in staypoints. To avoid including too large missing signal gaps, set ‘gap_threshold’ to a small value, e.g., 15 min.
Examples
>>> pfs.generate_staypoints('sliding', dist_threshold=100)
References
Zheng, Y. (2015). Trajectory data mining: an overview. ACM Transactions on Intelligent Systems and Technology (TIST), 6(3), 29.
Li, Q., Zheng, Y., Xie, X., Chen, Y., Liu, W., & Ma, W. Y. (2008, November). Mining user similarity based on location history. In Proceedings of the 16th ACM SIGSPATIAL international conference on Advances in geographic information systems (p. 34). ACM.
- trackintel.preprocessing.generate_triplegs(positionfixes, staypoints=None, method='between_staypoints', gap_threshold=15)[source]
Generate triplegs from positionfixes.
- Parameters:
positionfixes (Positionfixes) – If ‘staypoint_id’ column is not found, ‘staypoints’ needs to be provided.
staypoints (Staypoints, optional) – The staypoints (corresponding to the positionfixes). If this is not passed, the positionfixes need ‘staypoint_id’ associated with them.
method ({'between_staypoints', 'overlap_staypoints'}) – Method to create triplegs. ‘between_staypoints’ method defines a tripleg as all positionfixes between two staypoints (no overlap). ‘overlap_staypoints’ method defines a tripleg as all positionfixes between two staypoints and includes the coordinates of the staypoints. The latter method require positionfixes to have the ‘staypoint_id’ column and passing staypoints as an input.
gap_threshold (float, default 15 (minutes)) – Maximum allowed temporal gap size in minutes. If tracking data is missing for more than gap_threshold minutes, a new tripleg will be generated.
- Returns:
pfs (Positionfixes) – The original positionfixes with a new column
[`tripleg_id`].tpls (Triplegs) – The generated triplegs.
Notes
The methods require either a column ‘staypoint_id’ on the positionfixes or passing some staypoints that correspond to the positionfixes! This means you usually should call
generate_staypoints()first.- Following the assumptions in the function generate_staypoints(), to ensure consistency, the time extend and geometry for triplegs is defined as follows:
‘between_staypoints’: The generated tripleg will not have overlapping pf with the existing sps, thus triplegs’ ‘geometry’ does not have common pf as sps. ‘started_at’ is the timestamp of the first pf after a sp, and ‘finished_at’ is the time of the last pf before a sp. This means a temporal gap will occur between the first pf of sp and the last pf of tripleg: pfs_stp_first[‘tracked_at’] - pfs_tpl_last[‘tracked_at’] != 0. No temporal gap will occur between sp ends and tripleg starts (as per sp time definition).
‘overlap_staypoints’: The generated tripleg will have common start and end point geometries with the existing sps. ‘started_at’ is the timestamp of the first pf after a sp (same as ‘between_staypoints’, to be consistent with generate_staypoints()), and ‘finished_at’ is the time of the first pf of a following sp. Temporal gaps will not occur between sps and triplegs.
Examples
>>> pfs.generate_triplegs('between_staypoints', gap_threshold=15)
Staypoints
Staypoints are points where someone stayed for a longer period of time (e.g., during a transfer between two transport modes). We can cluster these into locations that a user frequently visits and/or infer if they correspond to activities.
- trackintel.preprocessing.generate_locations(staypoints, method='dbscan', epsilon=100, num_samples=1, distance_metric='haversine', agg_level='user', activities_only=False, print_progress=False, n_jobs=1)[source]
Generate locations from the staypoints.
- Parameters:
staypoints (Staypoints)
method ({'dbscan'}) –
Method to create locations.
dbscan : Uses the DBSCAN algorithm to cluster staypoints.
epsilon (float, default 100) – The epsilon for the ‘dbscan’ method. if ‘distance_metric’ is ‘haversine’ or ‘euclidean’, the unit is in meters.
num_samples (int, default 1) – The minimal number of samples in a cluster.
distance_metric ({'haversine', 'euclidean'}) – The distance metric used by the applied method. Any mentioned below are possible: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.pairwise_distances.html
agg_level ({'user','dataset'}) –
The level of aggregation when generating locations:
user: locations are generated independently per-user.
dataset: shared locations are generated for all users.
activities_only (bool, default False (requires "activity" column)) – Flag to set if locations should be generated only from staypoints on which the value for “activity” is True. Useful if activites represent more significant places.
print_progress (bool, default False) – If print_progress is True, the progress bar is displayed
n_jobs (int, default 1) – The maximum number of concurrently running jobs. If -1 all CPUs are used. If 1 is given, no parallel computing code is used at all, which is useful for debugging. See https://joblib.readthedocs.io/en/latest/parallel.html#parallel-reference-documentation for a detailed description
- Returns:
sp (Staypoints) – The original staypoints with a new column
[`location_id`].locs (Locations) – The generated locations, with geometry columns
[`center` (default geometry), `extent`]. Depending on the contained staypoints, center is their centroid, and extent is their convex hull with a buffer distance of epsilon.
Examples
>>> sp.generate_locations(method='dbscan', epsilon=100, num_samples=1)
Due to tracking artifacts, it can occur that one activity is split into several staypoints. We can aggregate the staypoints horizontally that are close in time and at the same location.
- trackintel.preprocessing.merge_staypoints(staypoints, triplegs, max_time_gap='10min', agg={})[source]
Aggregate staypoints horizontally via time threshold.
- Parameters:
staypoints (Staypoints) – The staypoints must contain a column location_id (see generate_locations function)
triplegs (Triplegs)
max_time_gap (str or pd.Timedelta, default "10min") – Maximum duration between staypoints to still be merged. If str must be parsable by pd.to_timedelta.
agg (dict, optional) – Dictionary to aggregate the rows after merging staypoints. This dictionary is used as input to the pandas aggregate function: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.agg.html If empty, only the required columns of staypoints (which are [‘user_id’, ‘started_at’, ‘finished_at’]) are aggregated and returned. In order to return for example also the geometry column of the merged staypoints, set ‘agg={“geom”:”first”}’ to return the first geometry of the merged staypoints, or ‘agg={“geom”:”last”}’ to use the last one.
- Returns:
sp – The new staypoints with the default columns and columns in agg, where staypoints at same location and close in time are aggregated.
- Return type:
Notes
Due to the modification of the staypoint index, the relation between the staypoints and the corresponding positionfixes is broken after execution of this function! In explanation, the staypoint_id column of pfs does not necessarily correspond to an id in the new sp table that is returned from this function. The same holds for trips (if generated yet) where the staypoints contained in a trip might be merged in this function.
If there is a tripleg between two staypoints, the staypoints are not merged. If you for some reason want to merge such staypoints, simply pass an empty DataFrame for the tpls argument.
Examples
>>> # direct function call >>> ti.preprocessing.merge_staypoints(staypoints=sp, triplegs=tpls) >>> # or using the trackintel datamodel >>> sp.merge_staypoints(triplegs, max_time_gap="1h", agg={"geom":"first"})
Triplegs
Triplegs denote routes taken between two consecutive staypoint. Usually, these are traveled with a single mode of transport.
From staypoints and triplegs, we can generate trips that summarize all movement and all non-essential actions (e.g., waiting) between two relevant activity staypoints.
- trackintel.preprocessing.triplegs.generate_trips(staypoints, triplegs, gap_threshold=15, add_geometry=True)[source]
Generate trips based on staypoints and triplegs.
- Parameters:
staypoints (Staypoints)
triplegs (Triplegs)
gap_threshold (float, default 15 (minutes)) – Maximum allowed temporal gap size in minutes. If tracking data is missing for more than gap_threshold minutes, then a new trip begins after the gap.
add_geometry (bool default True) – If True, the start and end coordinates of each trip are added to the output table in a geometry column “geom” of type MultiPoint. Set add_geometry=False for better runtime performance (if coordinates are not required).
print_progress (bool, default False) – If print_progress is True, the progress bar is displayed
- Returns:
sp (Staypoints) – The original staypoints with new columns
[`trip_id`, `prev_trip_id`, `next_trip_id`].tpls (Triplegs) – The original triplegs with a new column
[`trip_id`].trips (Trips) – The generated trips.
Notes
Trips are an aggregation level in transport planning that summarize all movement and all non-essential actions (e.g., waiting) between two relevant activities. The function returns altered versions of the input staypoints and triplegs. Staypoints receive the fields [trip_id prev_trip_id and next_trip_id], triplegs receive the field [trip_id]. The following assumptions are implemented
If we do not record a person for more than gap_threshold minutes, we assume that the person performed an activity in the recording gap and split the trip at the gap.
Trips that start/end in a recording gap can have an unknown origin/destination
There are no trips without a (recorded) tripleg
Trips optionally have their start and end point as geometry of type MultiPoint, if add_geometry==True
If the origin (or destination) staypoint is unknown, and add_geometry==True, the origin (and destination) geometry is set as the first coordinate of the first tripleg (or the last coordinate of the last tripleg), respectively. Trips with missing values can still be identified via col origin_staypoint_id.
Examples
>>> from trackintel.preprocessing import generate_trips >>> staypoints, triplegs, trips = generate_trips(staypoints, triplegs)
trips can also be directly generated using the tripleg class method >>> staypoints, triplegs, trips = triplegs.generate_trips(staypoints)
The function generate_trips follows this algorithm:
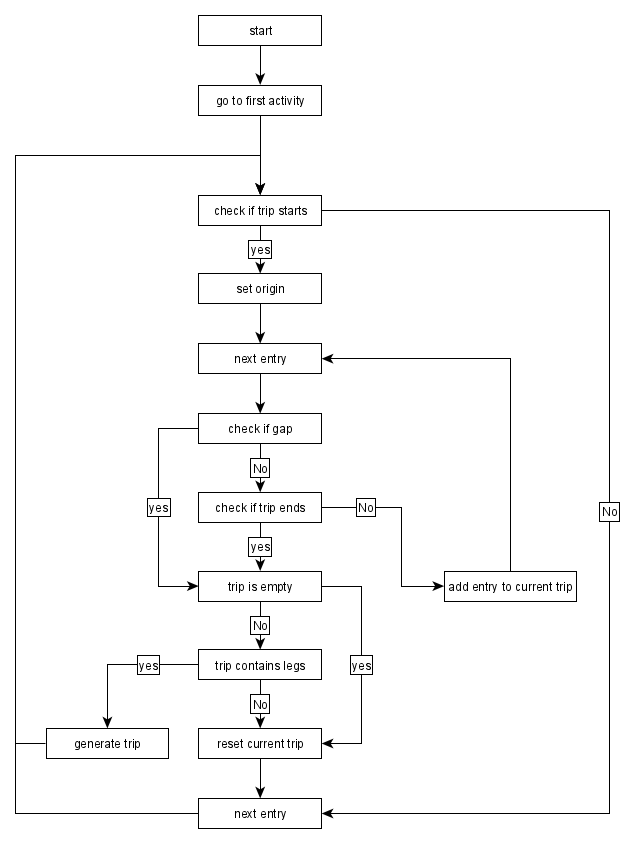
Trips
Trips denote the sequence of all triplegs between two consecutive activities. These can be composed of multiple means of transports. A further aggregation of Trips are Tours, which is a sequence of trips such that it starts and ends at the same location. Using the trips, we can generate tours.
- trackintel.preprocessing.generate_tours(trips, staypoints=None, max_dist=100, max_time='1D', max_nr_gaps=0, print_progress=False, n_jobs=1)[source]
Generate trackintel-tours from trips
- Parameters:
trips (Trips)
staypoints (Staypoints, default None) – Must have location_id column to connect trips via locations to a tour. If None, trips will be connected based only by the set distance threshold max_dist.
max_dist (float, default 100 (meters)) – Maximum distance between the end point of one trip and the start point of the next trip within a tour. This is parameter is only used if staypoints is None! Also, if max_nr_gaps > 0, a tour can contain larger spatial gaps (see Notes below for more detail)
max_time (str or pd.Timedelta, default "1D" (1 day)) – Maximum time that a tour is allowed to take
max_nr_gaps (int, default 0) – Maximum number of spatial gaps on the tour. Use with caution - see notes below.
print_progress (bool, default False) – If print_progress is True, the progress bar is displayed
n_jobs (int, default 1) – The maximum number of concurrently running jobs. If -1 all CPUs are used. If 1 is given, no parallel computing code is used at all, which is useful for debugging. See https://joblib.readthedocs.io/en/latest/parallel.html#parallel-reference-documentation for a detailed description
- Returns:
trips_with_tours (Trips) – Same as trips, but with column tour_id, containing a list of the tours that the trip is part of (see notes).
tours (Tours) – The generated tours
Examples
>>> trips.generate_tours(staypoints)
Notes
Tours are defined as a collection of trips in a certain time frame that start and end at the same point
Tours and trips have an N:N relationship: One tour consists of multiple trips, but also one trip can be part of multiple tours, due to nested tours or overlapping tours.
This function implements two possibilities to generate tours of trips: Via the location ID in the staypoints df, or via a maximum distance. Thus, note that only one of the parameters staypoints or max_dist is used!
Nested tours are possible and will be regarded as 2 (or more tours).
It is possible to allow spatial gaps to occur on the tour, which might be useful to deal with missing data. Example: The two trips home-work, supermarket-home would still be detected as a tour when max_nr_gaps >= 1, although the work-supermarket trip is missing. Warning: This only counts the number of gaps, but neither temporal or spatial distance of gaps, nor the number of missing trips in a gap are bounded. Thus, this parameter should be set with caution, because trips that are hours apart might still be connected to a tour if max_nr_gaps > 0.
Trips and Tours have an n:n relationship: One tour consists of multiple trips, but due to nested or overlapping tours, one trip can also be part of mulitple tours. A helper function can be used to get the trips grouped by tour.
- trackintel.preprocessing.trips.get_trips_grouped(trips, tours)[source]
Helper function to get grouped trips by tour id
- Parameters:
- Returns:
trips_grouped_by_tour – Trips grouped by tour id
- Return type:
DataFrameGroupBy object
Examples
>>> get_trips_grouped(trips, tours)
Notes
This function is necessary because when running generate_tours, one trip only gets the tour ID of the smallest tour it belongs to assigned. Here, we return all trips for each tour, which might contain a nested tour.
Utils
- trackintel.preprocessing.calc_temp_overlap(start_1, end_1, start_2, end_2)[source]
Calculate the portion of the first time span that overlaps with the second.
- Parameters:
start_1 (datetime) – start of first time span
end_1 (datetime) – end of first time span
start_2 (datetime) – start of second time span
end_2 (datetime) – end of second time span
- Returns:
The ratio by which the first timespan overlaps with the second.
- Return type:
Examples
>>> ti.preprocessing.calc_temp_overlap(start_1, end_1, start_2, end_2)
- trackintel.preprocessing.applyParallel(dfGrouped, func, n_jobs, print_progress, **kwargs)[source]
Funtion warpper to parallelize funtions after .groupby().
- Parameters:
dfGrouped (pd.DataFrameGroupBy) – The groupby object after calling df.groupby(COLUMN).
func (function) – Function to apply to the dfGrouped object, i.e., dfGrouped.apply(func).
n_jobs (int) – The maximum number of concurrently running jobs. If -1 all CPUs are used. If 1 is given, no parallel computing code is used at all, which is useful for debugging. See https://joblib.readthedocs.io/en/latest/parallel.html#parallel-reference-documentation for a detailed description
print_progress (boolean) – If set to True print the progress of apply.
**kwargs – Other arguments passed to func.
- Returns:
The result of dfGrouped.apply(func)
- Return type:
pd.DataFrame
Examples
>>> from trackintel.preprocessing.util import applyParallel >>> applyParallel(tpfs.groupby("user_id", as_index=False), func, n_jobs=2)